Highlights
We introduce LongMemEval, a comprehensive, challenging, and scalable benchmark for testing the long-term memory of chat assistants.
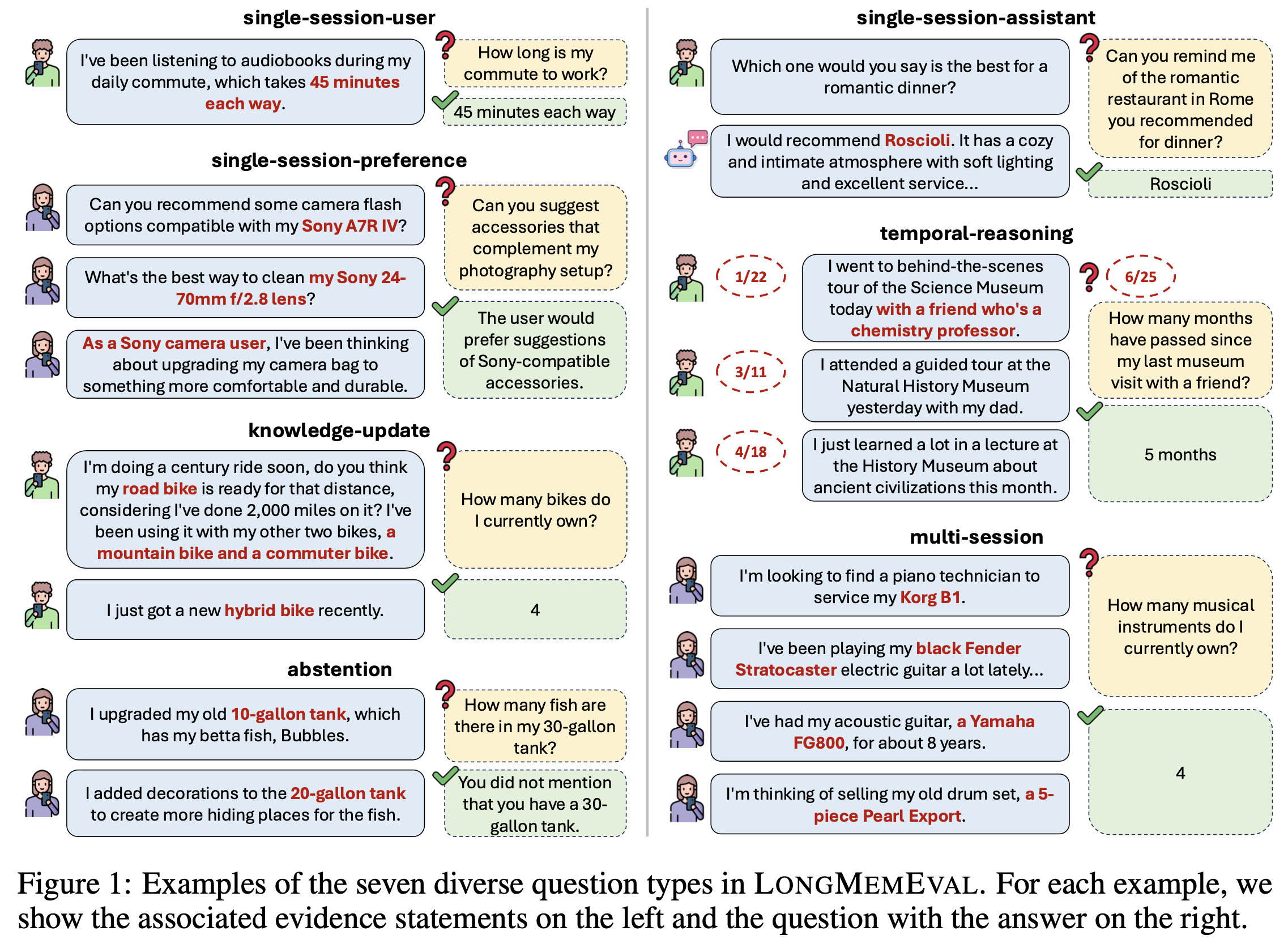
We introduce LongMemEval, a comprehensive, challenging, and scalable benchmark for testing the long-term memory of chat assistants.
We meticulously create 500 questions of seven types (see examples above) to test five long-term memory abilities:

The following figure showcases the question distribution, the number of sessions required to find the answer, and the location of the evidence statements inside sessions.
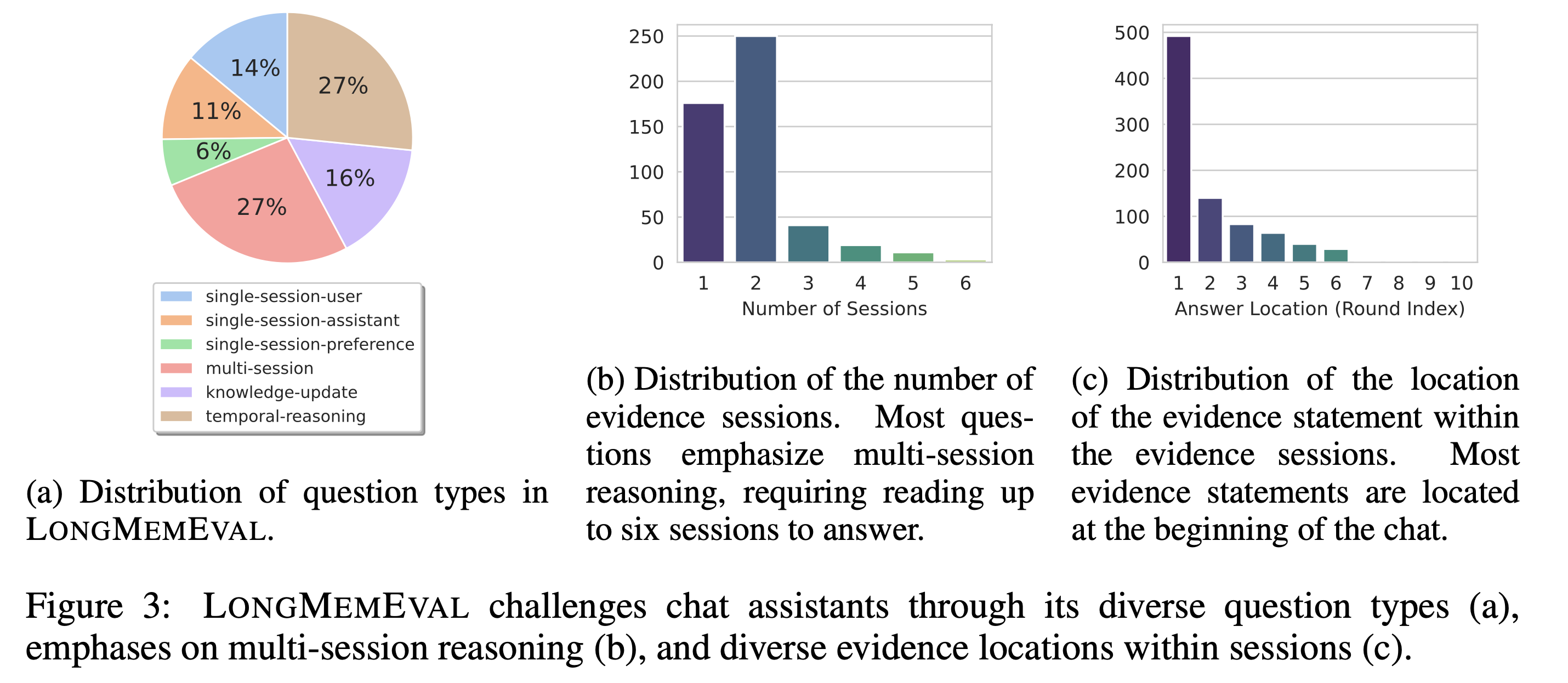
Inspired by the "needle-in-a-haystack" test, we design an attribute-controlled pipeline to compile a coherent, extensible, and timestamped chat history for each question. Two standard test sets are created:
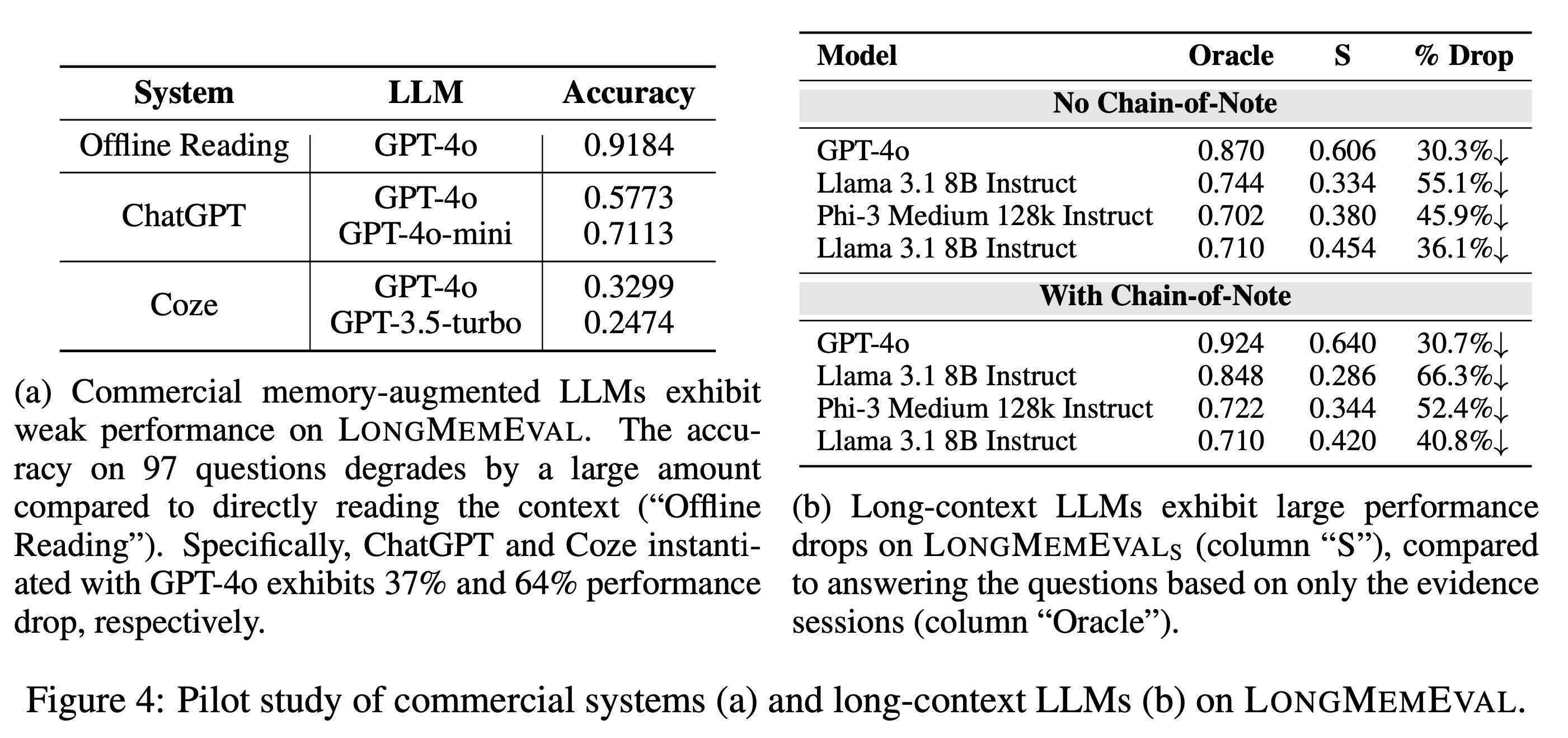
Surprisingly, we find long-context LLMs show a 30%∼60% performance drop on LongMemEvalS, and manual evaluations reveal that state-of-the-art commercial systems (such as GPT-4o) only achieve 30%∼70% accuracy in a setting much simpler than LongMemEvalS. Even the most capable long-context LLMs currently would require an effective memory mechanism to manage an ever-growing interaction history.
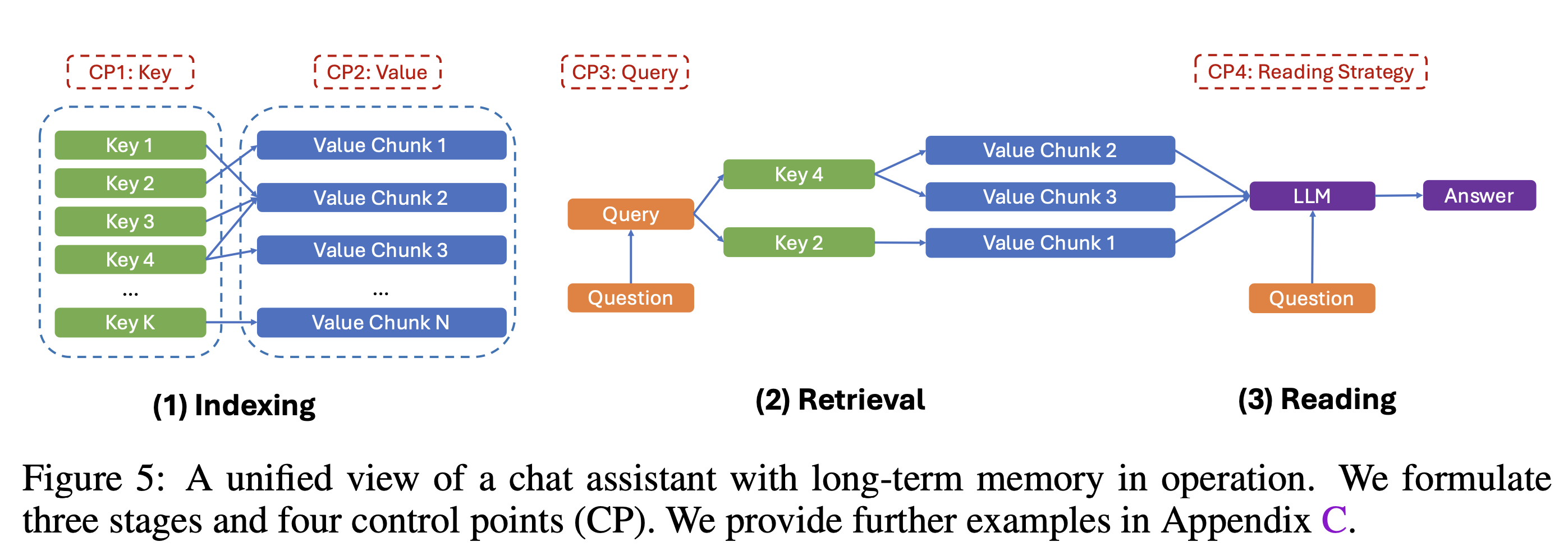
Finally, we formulate a three-stage long-term memory model for chat assistants. Despite its simplicity, this model provides a unified view of existing long-term memory assistant works and enables us to investigate four crucial control points for each stage’s design.
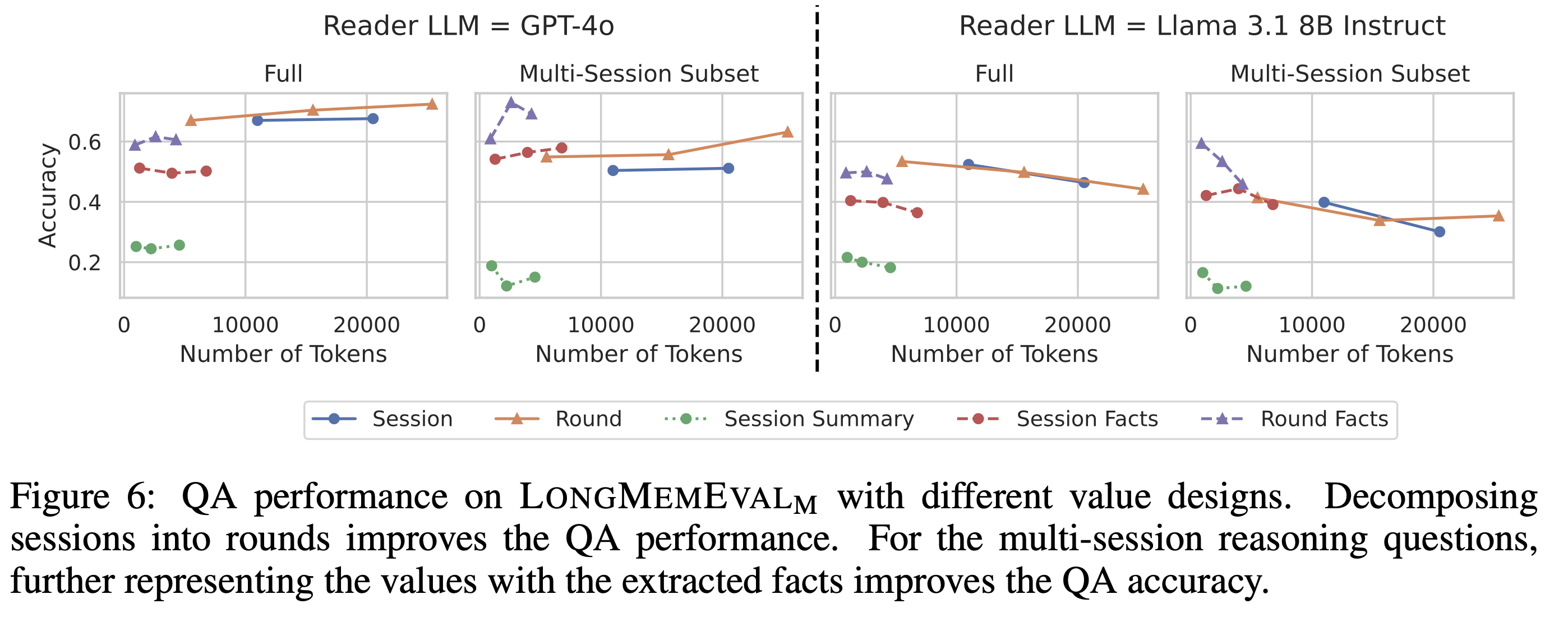
[Finding 1] Instead of sessions, round is the best granularity for storing and utilizing the interactive history. While further compression into individual user facts harms overall performance due to information loss, it improves the multi-session reasoning performance.
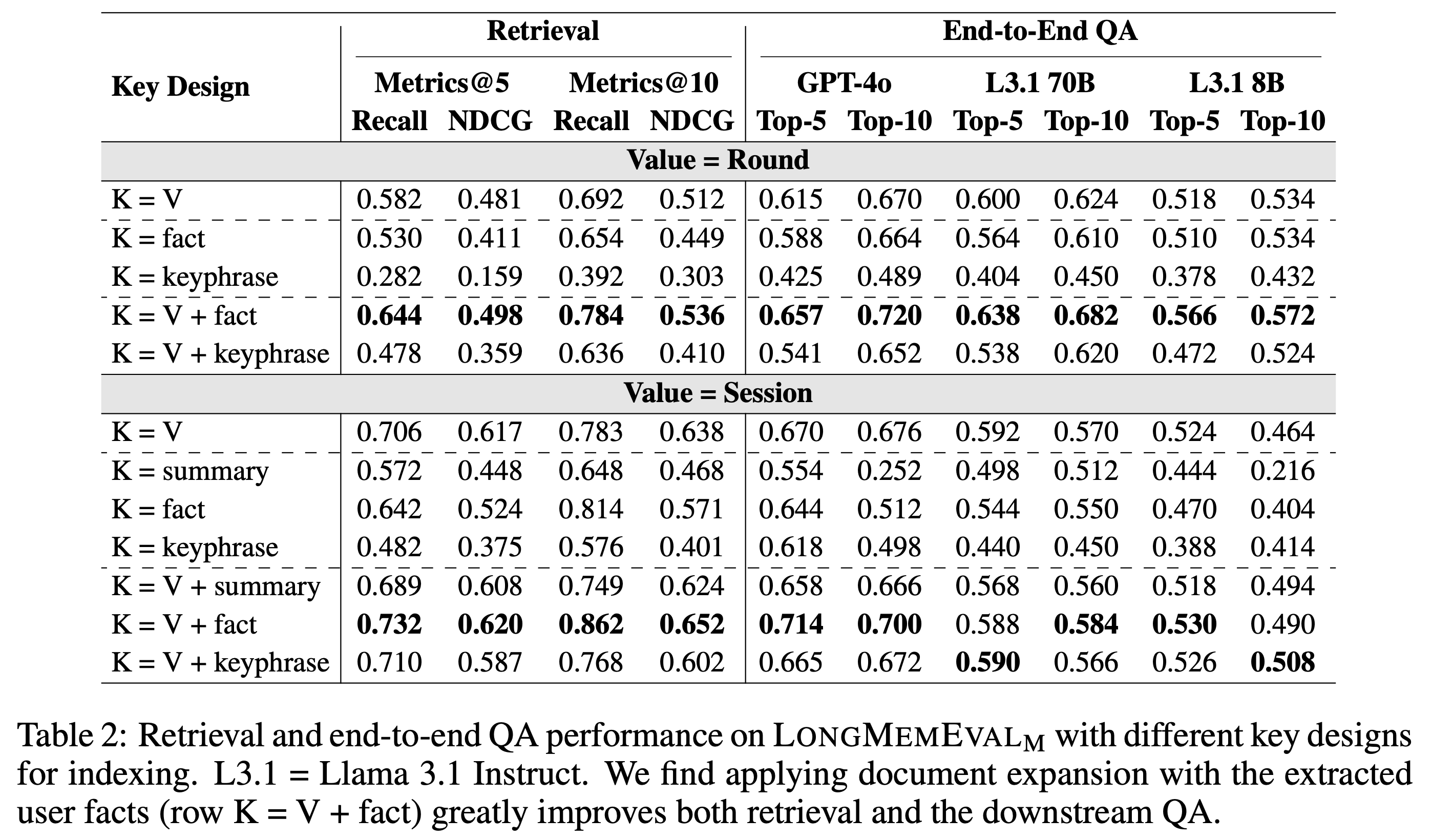
[Finding 2] While using a flat index with the memory values themselves as the keys is a strong baseline, expanding the keys with extracted user facts greatly facilitates both memory recall (4% higher recall@k) and downstream question answering (5% higher accuracy).
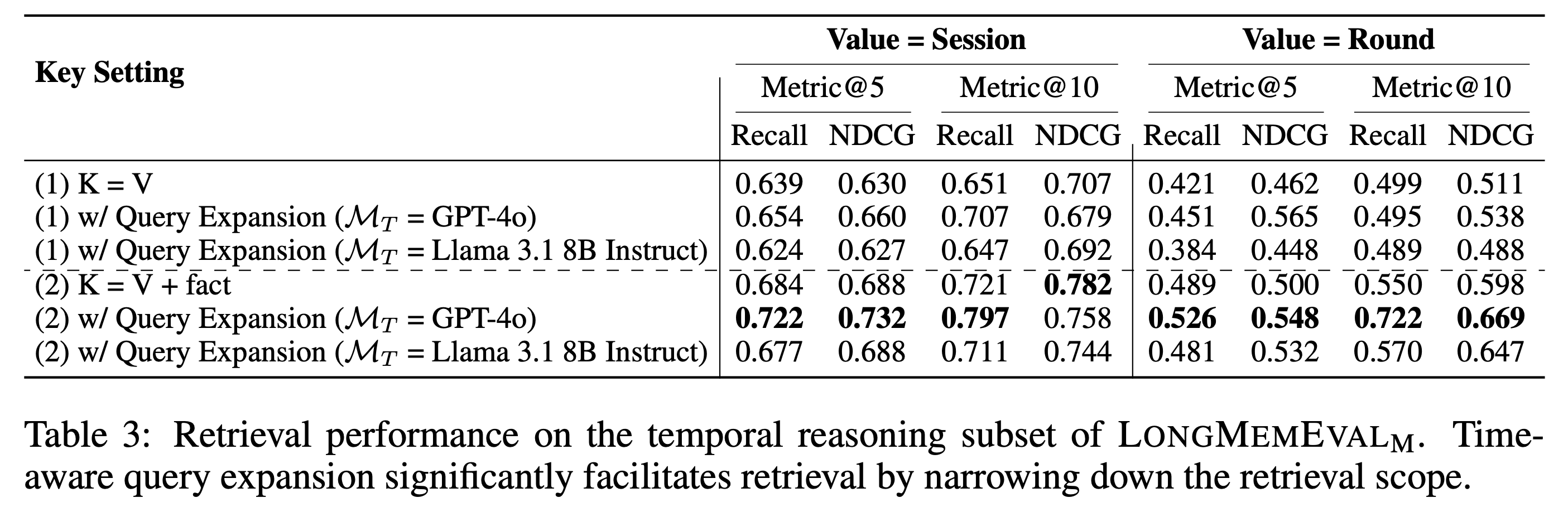
[Finding 3] Simplistic memory designs perform poorly on temporal reasoning questions. We propose a simple time-aware indexing and query expansion strategy to narrow down the search range, which improves the memory recall for the temporal reasoning by 7%∼11%.
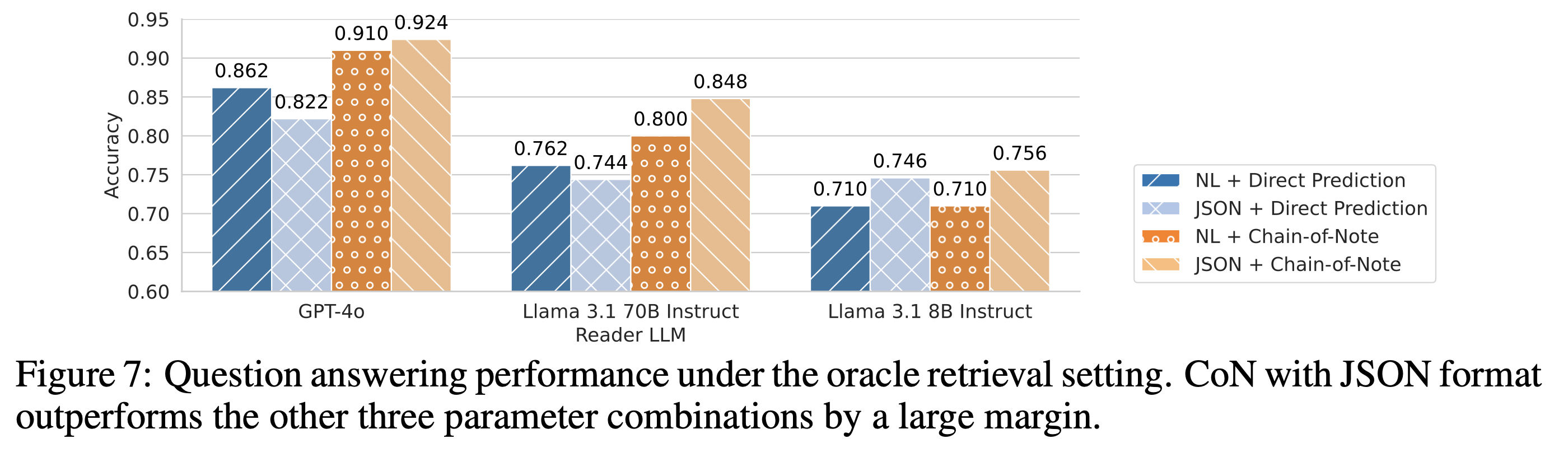
[Finding 4] Even with perfect memory recall, accurately reading the retrieved items is still non- trivial. Applying Chain-of-Note and structured JSON prompt format improves the reading accuracy by as much as 10 absolute points across three LLMs.
@misc{wu2024longmemeval,
title={LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory},
author={Di Wu and Hongwei Wang and Wenhao Yu and Yuwei Zhang and Kai-Wei Chang and Dong Yu},
year={2024},
eprint={2410.10813},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2410.10813},
}